
So what is this? Ilamaindex is an open source python library that uses large language models to aggregate collections of disparate documents to allow users to search them in some capacity.
This post will be about an implementation of llamaindex.
It works kind of like this:
- Creates an index with docs
- User enters query or requests a summary
- Then the index is used to find the info.
- The info is then passed to the LLM with your query in order to consider a broader scope
Can support files and web date. User indexes the query, which facilitates a search.
This sounds really neat! Will need a few packages and an openai key.
Grabbed my openAI API key and created the env/environmental variable. Took a restart, but we are rolling!
Code looks like this:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader(input_dir='augmented retrieval/documents').load_data()
index = VectorStoreIndex.from_documents(documents)
chat_engine = index.as_chat_engine(verbose=True)
chat_engine.chat_repl()To put this simply, this allows you to talk to your data via ChatGPT.
To demonstrate, I downloaded the most recent House and Senate appropriations bills. Then, using mostly just the code above, I was able to query both PDFs using plain English! Check this out:
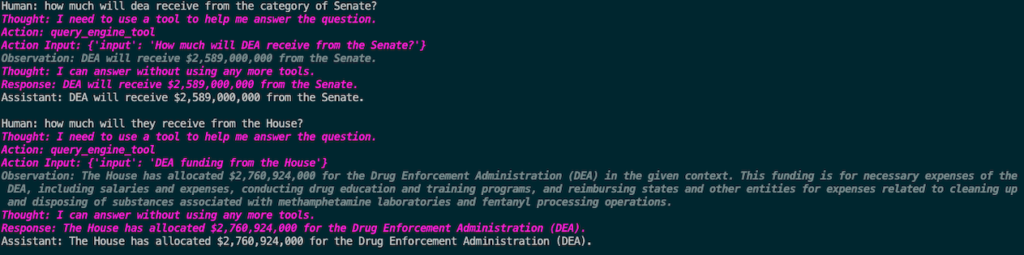
In this example, the underlying data was comprised of merely 2 pdfs. Sure, I could have CTRL+F’d my way to this answer, but what if I have 10,000 documents in various formats and structures, etc.? Through the use of vector embeddings and indexing functions, you can ingest xlsx, doc, pdf, api, etc etc etc and query ALL of them collectively for the information that you need.

p.s this is my first post to a wordpress in a long long time and things have changed. hopefully I am able to improve eventually.
p.p.s. 90% of what I know about llamaindex I learned from this zenva course. you might be able to score it for less via humblebundle.



0 Comments